
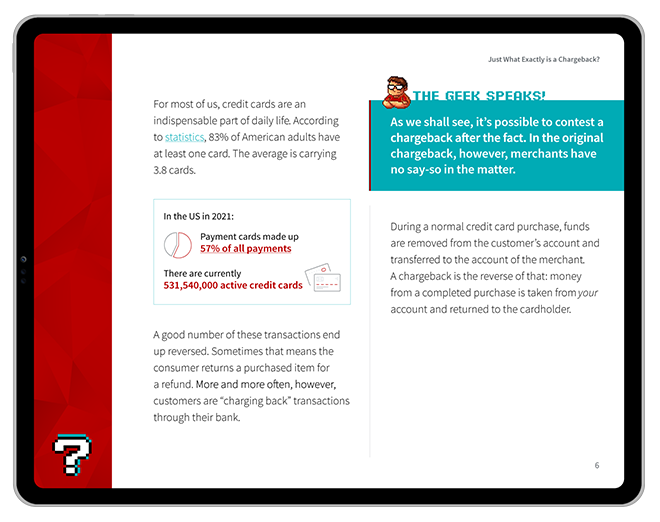
Will Machine Learning be Your Secret Weapon Against Both First- & Third-Party Fraud?
Fraudsters are getting smarter. By extension, the tactics they use are becoming more complex and harder to detect using conventional tools.
Advancements in technology have helped create this problem, but they may also provide the solution. As some merchants are starting to discover, fraud detection machine learning technology can help stop fraud before it happens in many cases.
Machine learning (ML) is exactly what it sounds like: computers use experience and data to automatically improve their own capabilities. The program tests incoming information to see if it either contradicts or reinforces an existing algorithm, then adjusts accordingly. The more data the machine receives, the more reliable its predictions will be.
There’s tremendous potential here… but is it right for your business? Let’s find out.
Recommended reading
- What are Velocity Checks? How Do They Stop Fraud Attacks?
- Card Security Codes: How They Protect Consumers & Merchants
- ECI Indicators: How to Understand 3DS Response Codes
- What is 3D Secure 2.0? How it Works & Why It’s Necessary
- V-Bucks Vanishing From Accounts Due to Triangulation Scam
- Managing Your Digital Footprint Can Stop Identity Theft
Fraud Detection & Machine Learning
Machine learning is often described as “artificial intelligence.” This is because it appears to give computers the ability to learn the same way that humans learn. In reality, instead of trying to mimic human thinking, machine learning simply compares facts and draws the most logical conclusions. So, while machine learning uses AI to operate, not every AI uses machine learning.
The computer is not literally “thinking” in the same way as a human. However, every new bit of information helps refine the algorithm. This makes the computer “smarter” in a real sense.
The machine learning model of fraud detection is a technology-powered strategy that compares incoming information against historical data prior to approving a transaction. The machine learning model uses sophisticated algorithms to analyze results, effectively “learning” from each new input.
Conventional (“Rules-Based”) Fraud Detection vs. Machine Learning
| Rule-Based Fraud Detection | ML Fraud Detection |
| Detects obvious fraud incidents | Finds hidden correlations in data |
| Requires manual oversight to develop rules | Develops rules based on observed data trends |
| Multiple verification steps introduce friction | Minimizes customer-facing “negative” friction |
| Long-term processing | Real-time processing |
For fraud detection, specifically, they can be trained using examples of good and bad transactions. And, with more training, it’s able to identify fraud activity in real-time with more information. Thus, the system gets better and more accurate over time.
The model calculates a score that reflects the transaction’s fraud risk based on everything it learns. The final score is compiled from multiple elements, with different factors weighted more heavily than others, and is used to make a decision: accept the transaction, reject it, or flag it for manual review by a human.

The entire decisioning process typically takes less than a second. The customer is totally unaware that it even happened. The information extracted from the transaction is then fed back into the model, further refining the algorithm.
Industry Uses for Fraud Detection in Machine Learning
Machine learning models are already known for their ability to help businesses break down data and create specific, measurable, attainable, realistic, and timely (or “SMART”) goals and action plans. AI-driven fraud prevention transcends industries, requiring only data to function effectively.
Machine learning fraud detection implementation can already be seen in a number of sectors, including:
Securing Digital Wallets & Combating ATO Attacks
As Buy Now Pay Later (BNPL) accounts evolve into online digital wallets, the risk of account takeover (ATO) attacks increases. Fraudsters can exploit compromised accounts to make illegal purchases. The key to safeguarding these accounts lies in understanding user login patterns, which can vary significantly based on factors like market and seasonality. Using machine learning to analyze login data can improve user authentication and enhance account security.
Compliance & Fraud Detection for Financial Institutions
Fintech firms, traditional financial institutions, and insurance providers must adhere to stringent compliance requirements to avoid regulatory penalties. They need to ensure they are interacting with genuine users, not fraudsters. To stay competitive, these institutions must act swiftly, which can sometimes lead to fraudulent profiles slipping through the cracks. Implementing a machine learning system can provide invaluable insights to distinguish between legitimate and fake user profiles.
Tackling Bonus Abuse and Multi-Accounting
Online gaming platforms and betting sites must ensure their players are genuine while also offering enticing rewards to new customers. This dual objective creates opportunities for fraudsters to engage in multi-accounting, claiming signup bonuses, and collusive play. Machine learning systems can analyze data to identify suspicious user behavior, detecting poker bots, cheating players, and low-quality traffic from dishonest affiliates.
eCommerce Fraud Prevention for Online Retail
Scrutinizing thousands of transactions can be a daunting task for eCommerce fraud managers. Machine learning can help identify the reasons why certain transactions weren't initially flagged as fraudulent. Leveraging machine learning can reveal which products are frequently targeted by fraudsters. It can also point out high-risk shipping information, and which card payments should be blocked to reduce chargeback rates.
Streamlining Gateway Security
Manually reviewing every transaction is impractical for payment gateways, especially when speed is critical. Processing thousands of transactions quickly makes human intervention virtually impossible. Machine learning engines can serve as a fraud monitoring analytics system and be trained to detect fraudulent transactions and prevent chargeback costs (specifically, for “non-authorized” chargebacks).
What Problems Does Machine Learning Solve?
In order to get the most out of a machine learning system, you need to know what you’re targeting. It’s helpful to see how a machine learning fraud detection model can work on a practical level. So, let’s look at some examples of how it can be applied in some real-world scenarios.
Account Takeover
The Threat Posed
Criminals try to hijack a card account, locking out the legitimate owner.What Machine Learning Does
Blocks any password or identity changes without owner permission.Email Phishing
The Threat Posed
Fraudsters trick victims into answering fake emails with personal data.What Machine Learning Does
Recognizes and denies “spam” email addresses.Synthetic Fraud
The Threat Posed
Combining personal data from multiple sources to create phony accounts.What Machine Learning Does
Detects when account details are mismatched.Stolen Credit Cards
The Threat Posed
Using stolen cardholder details to make card-not-present purchases.What Machine Learning Does
Requires verification for purchases inconsistent with customer historical data.These are just a few examples. However, they help illustrate a wide range of advantages offered by machine learning fraud detection technology.

Advantages of Using Machine Learning to Detect Credit Card Fraud
As we established, machine learning fraud detection technology works by comparing new information against what it already knows. Humans go about the decision-making process in the same way, so why rely on a machine?
Well, ML technology offers a few key advantages:
- It’s Faster: Robust machine learning algorithms can analyze complex transaction data and render a risk score in a split second.
- It’s More Accurate: ML models analyze much more information than a human can. They’re able to detect even subtle fraud patterns, free of human bias or error.
- It Gets Better: With good input, machine learning models will improve with each transaction. A machine learning fraud detection system grows with your business.
- It’s Proactive: ML models learn from bad actors and normal behavior. The algorithm can proactively identify fraud before a bad transaction gets processed.
- It Saves Money: A computer can run more comprehensive data checks than a room full of human analysts. It lets you reallocate staff where they’re most needed.
- It’s Adaptive: Legacy systems depend on preset, static responses. A fraud detection model, however, is designed to adapt to new information on its own.A brand new checklist item
Done correctly, fraud detection machine learning is a highly effective way to identify and prevent fraud. That doesn’t mean it’s perfect, though.
Are There Any Disadvantages to Adopting Machine Learning?
Fraudsters work tirelessly to find new ways to subvert the system. For example, finding new ways to mimic typical customer behavior. This can make any fraud indicators much more subtle and harder to recognize. There’s also the fact that machines are only as good as the input they have.
Any bad data can impact the algorithm results. And since transaction info is fed back into the model, it can cause serious issues over time. For example, if your system misidentifies a friendly fraud incident as genuine criminal fraud, that skews the decisioning matrix. Inaccurate data leads to bad decision making, so the ML system will keep making the same mistake over and over.
Despite the system’s benefits, there are instances where traditional manual reviews may be more suitable than automated systems:
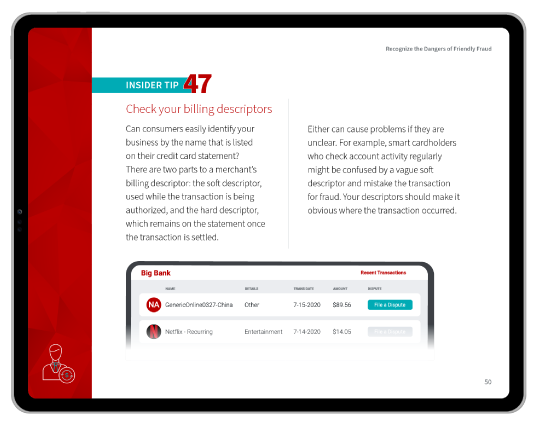
- Limited Control: “Black box” machine learning engines can occasionally make errors without detection. This lack of transparency and control can be concerning for businesses, particularly when these mistakes have significant consequences.
- False Positives: Because rules only allow “yes” or “no” decisions, it’s not uncommon for legitimate orders to get marked as fraud. This is a serious concern, as false declines cost merchants $443 billion every year.
- Absence of Human Insight: Understanding the underlying reasons behind suspicious user actions can sometimes require human intuition and psychological analysis. This is something that automated systems may struggle to replicate.
- Friendly Fraud: Since first-party abusers typically exhibit normal, non-fraudulent behavior patterns, it becomes difficult for machine learning algorithms to distinguish between genuine and friendly fraud transactions.
- High-Value Transactions: Manual reviews can be more reliable for high-stakes transactions. In these cases, human reviewers can provide an additional layer of scrutiny to verify the legitimacy of the transaction and minimize the risk of fraud.
While AI-driven fraud prevention offers numerous advantages, there are situations where manual reviews remain the preferred choice. Balancing the use of technology with human expertise can help businesses effectively mitigate risks and maintain a robust fraud prevention strategy.
How Does a Machine Learning System Work?
Machine learning systems work by learning to identify patterns indicative of fraud from historical data and applying that knowledge to new, unseen transactions. This is achieved through a combination of data preprocessing, feature engineering, model selection, training, evaluation, and deployment.
Here's an overview of the process:
You should have a better understanding of how this system works to help you identify and flag fraudulent transactions. So now, let's discuss how you can mold the system to your individual needs.
As we’ll explore below, there are essentially two stages to the process: building the model and implementing it.
How to Implement a Machine Learning Model for Fraud Detection
To get started, you will need as much transaction data as possible. This will establish a baseline for acceptable customer behavior. If your data set is too small for accurate learning, some providers will create “starter sets” of data from businesses similar to yours.
Next, the machine learning fraud detection system will pull specific data points from each transaction and add them to the model. This may include personal customer information, order and payment details, the location and network of the order, and so on. For a fraud detection model, all this information will need to be labeled as “good” or “bad.”
You now have the raw data to build your model. However, you still need to create an algorithm that helps the machine recognize the difference between “good” and “bad” transactions. Basically, you have to teach it the parameters for determining the legitimacy of a transaction.

Three Common Machine Learning Models
We've explored general fraud situations. Now let's dive into building machine learning applications and investigate typical and advanced methods for crafting fraud detection engines.
Anomaly Detection
Anomaly detection, a prevalent anti-fraud approach in data science, categorizes data objects into two groups: normal distribution and outliers. Outliers transactions are those that deviate from the norm and may be fraudulent.
- Are clients using services as expected?
- Are user actions and transactions typical?
- Are there inconsistencies in user-provided information?
This approach provides simple binary answers, useful for situations like requesting additional verification for suspicious transactions. While it may not expose fraud, it supports existing rule-based systems.
Supervised Learning
Supervised learning trains algorithms using labeled historical data. The goal is to predict target variables in future data.
Supervised learning models help create and improve business applications, including:
- Image and Object Recognition: Identifying and classifying objects from videos or images
- Predictive Analytics: Building systems that offer insights into business data points, enabling informed decision-making
- Customer Sentiment Analysis: Extracting and classifying information from large data volumes for understanding customer interactions
- Spam Detection: Using algorithms to manage spam and non-spam communications effectively
Unsupervised Learning
Unsupervised learning models process unlabeled data, classify it into subsets and detect hidden relationships between data item variables. This process includes:
- Clustering: Grouping unlabeled data based on similarities or differences
- Association Rulesets: Discovering correlations between dataset variables
- Dimensionality Reduction: Reducing data inputs while maintaining dataset integrity
Unsupervised learning allows for rapid pattern detection in large data volumes. Common real-world applications of unsupervised learning are:
- Computer Vision: Performing visual perception tasks, such as object recognition
- Medical Imaging: Facilitating quick and accurate patient diagnosis in radiology and pathology
- Customer Personas: Creating accurate buyer persona profiles to tailor product messaging
- Recommendation Engines: Developing efficient cross-selling strategies based on past purchase behavior data
Advanced systems can detect anomalies and recognize patterns that signify specific fraud scenarios. Anomaly detection, supervised learning, and unsupervised learning are widely used in anti-fraud systems, either individually or combined, to create more sophisticated anomaly detection algorithms.
The Proper Role of Machine Learning Technology
Machine learning has an important role to play in ensuring data integrity and identifying post-transaction threats like friendly fraud, return fraud, and cyber shoplifting. That role is very different from conventional fraud detection machine learning, though.
Using machine learning for more intelligent chargeback source detection lets you:
- Look beyond reason codes to find the true sources of chargebacks
- Be more proactive about future disputes
- Identify new revenue opportunities
- Reduce fees, overhead, and other costs
- Eliminate false positives and accept more transactions
An end-to-end solution powered by machine learning fraud detection technology is the only way to see true revenue recovery and sustainable growth.
FAQs
How can machine learning detect fraud?
The program tests incoming information to see if it either contradicts or reinforces an existing algorithm, then adjusts accordingly. The more data the machine receives, the more reliable its predictions will be.
What are the three different real-time machine learning fraud detection methods?
Three common models for real-time machine learning fraud detection include anomaly detection, which is aimed at detecting data outliers that deviate from normal patterns, as well as supervised and unsupervised machine learning. The former involves an algorithm trained to recognize patterns and determine outcomes, while the latter relies on an algorithm that processes unlabeled data to detect hidden relations between data points.
How can banks use machine learning for fraud detection?
Machine learning fraud detection offers advantages over traditional, rules-based fraud solutions as well. Legacy systems depend on absolute “yes/no” answers. This means someone must constantly monitor, review, and update the technology manually. A fraud detection machine learning model, however, is designed to adapt to new information on its own.








